

March 24, 2026
.jpg)
Anais Dotis • Mar 24, 2026
Learn to manage CPU resources in Kubernetes to ensure smooth workloads, optimize performance, make strategic CPU choices, and monitor CPU throttling.
.jpeg)
Picture this: You're happily driving along in your car when you suddenly start slowing down for no discernible reason. Even if you press the petal closer to the floor, you continue to decelerate. You're being throttled by a force beyond your control.
That doesn't actually happen with cars. But it does happen in Kubernetes, due to a process called CPU throttling. By restricting the amount of CPU available to containers, throttling slows them down.
CPU throttling happens in order to prevent the system from crashing due to exhaustion of CPU resources. But it can also negatively impact performance – which is why it's important to understand how to manage these resources in Kubernetes in ways that keep workloads running smoothly, without unexpected throttling events.
In Kubernetes, CPU throttling is the implementation of restrictions on how many CPU resources a container can consume. CPU throttling typically happens automatically when the amount of resources that a container is using approaches the maximum available to it. In that case, the system throttles CPU to avoid a crash.
In general, CPU throttling is not desirable. It slows down the performance of workloads because it reduces the amount of CPU available to them. This is better than having your system crash entirely due to inadequate CPU, but it's still a situation that you would ideally avoid by never running out of sufficient CPU.
Kubernetes won't actually shut down containers when CPU resources become constrained. It just throttles CPU to slow things down. This is notable because it's different from the way memory constraints are handled. Those can lead to forced workload shutdowns and Kubernetes OOMKilled errors.
To understand fully what CPU throttling means and how it works, let's dive a bit deeper into how Kubernetes manages CPUs, and what can happen when a cluster runs low on available CPU.
CPU refers to compute resources – meaning the part of a computer or server that can perform logic and run code. CPU is one of several resources (the other main ones being memory and persistent storage) that most workloads require to run.
.svg)
Kubernetes measures CPU resources in terms of units. As the K8s documentation explains, one CPU unit is equivalent to a virtual CPU core (if you're running your cluster on cloud servers) or one hyperthread on a bare-metal processor. Thus, the total CPU available to a cluster will depend on how many virtual or physical CPU cores are available from the nodes within the cluster.
Unless you tell it to do otherwise by configuring requests and CPU limits, which we'll explain below, Kubernetes defaults to trying to share available CPU among all workloads within a cluster. To do this, Kubernetes creates a pool of CPU units for each node, and then shares them dynamically with Pods running on that node. This results in what's known in Kubernetes jargon as a BestEffort Quality of Service (QoS) class. (We'll say more about QoS classes later in this article.)
As long as your nodes have enough available CPU units to support the Pods they are hosting, everything's great. But if your Pods require more CPU than is available, workload performance may degrade.
Running out of available CPU can happen in one of two ways:
Neither of these situations is desirable – which is why carefully managing CPU resources via throttling is important for avoiding potential performance issues in Kubernetes.
The main way to avoid overusing or overcommitting CPUs in Kubernetes is to set appropriate Kubernetes limits and requests. (This assumes, of course, that you have enough total CPU capacity in your cluster. If you don't, you'll need to add some nodes, or scale up the CPU assigned to existing nodes if possible.)
CPU limits and requests are Kubernetes features that work as follows:
Thus, by setting a request that provides sufficient CPU to your workloads, while also setting a CPU limit that prevents them from tying up so many CPU units that other workloads run out of enough CPU, you can avoid CPU throttling and the performance issues that come with it.
.svg)
The main types of resources that you can manage using limits and requests are CPU, memory, and hugepages (a type of memory unit on Linux).
You can assign limits and requests on a per-container or per-namespace basis. If you assign them to a container, they apply only to that specific container. If you assign them to a namespace, they apply to all containers hosted within that namespace.
You can't directly set a CPU limit or request for a Pod, but you can set limits and requests for all of the containers inside a Pod – which is what you'd have to do if you wanted to configure a minimum or maximum amount of CPU to be available to a Pod.
Noam Levy is a founding engineer at groundcover. Over the last 10 years, Noam has been a part of and led development teams focused on microservices-oriented web applications, monitoring complex application pipelines, and system engineering.
CPU throttling in Kubernetes is almost always caused by overly restrictive CPU limits rather than actual CPU exhaustion.
In many production clusters, removing CPU limits from latency-sensitive services significantly reduces tail latency and unexpected throttling.
To mitigate the risk of CPU throttling, you'll want to set CPU limits and requests that avoid the following conditions:
To set CPU limits and requests, simply define the desired values when writing the spec for a container or namespace. For example:
spec:
containers:
- name: some-container
image: some-image
resources:
limits:
cpu: "4"
requests:
cpu: "2"This sets a CPU limit of 4 units and a request of 2 for the container named some-container.
As we mentioned above, you can't explicitly set requests or limits for entire Pods. You instead need to set requests and limits for each container within a Pod.
Kubernetes doesn't notify you when CPU throttling happens. Nor does it provide native tooling to detect throttling events. There is no kubectl command you can run to check whether any containers are experiencing CPU throttling, for instance.
This means that the best way to monitor CPU throttling in Kubernetes is using a third-party Kubernetes monitoring tool that reports CPU throttling metrics. For instance, you can monitor container CPU throttling using Grafana.
You can also gain some sense of when CPU throttling might be occurring by monitoring other data that Kubernetes does report natively. For example, the kubectl top command will display data about CPU utilization, among other resources. It won't tell you whether throttling is happening, but if CPU usage is near 100 percent for an extended period, it's likely that throttling is happening.
CPU throttling troubleshooting
If you detect CPU throttling, work through the following steps to troubleshoot the issue:
The following best practices can help reduce the risk of running into CPU throttling issues in the first place.
Again, requests and limits are your primary line of defense against CPU throttling. Unless you have so much spare CPU capacity in your cluster that running low on CPU is unimaginable, setting appropriate requests and limits will help ensure that CPU is shared efficiently across workloads.
Some workloads may be more important than others. Requests and limits should reflect this by ensuring that critical workloads receive priority during CPU assignment.
For instance, if you have a dev/test namespace in your cluster, it may make sense to set a relatively low CPU limit and request for that namespace. Throttling for dev/test workloads is probably not as serious as the throttling of production workloads.
Quality of Service (QoS) classes are another way to prioritize some workloads over others. You can configure three classes:
QoS classes won't necessarily protect against CPU throttling. A workload in the Guaranteed class could still be throttled. However, they are another way of helping to distribute CPU efficiently and based on workload priority, reducing the risk of throttling.
Kubernetes supports autoscaling features, which can automatically reconfigure workloads based on resource consumption patterns and requirements. There are two types of autoscalers:
Like QoS classes, autoscaling won't guarantee that CPU throttling never happens. But it can help to balance demand and prevent throttling incidents. For example, by spreading replicas of a Pod across multiple nodes to balance load, horizontal autoscaling can help prevent a single Pod instance from maxing out its node's CPU. Vertical autoscaling can add more total CPU before CPU becomes exhausted.
Managing Kubernetes CPU throttling with groundcovergroundcover helps you gain the critical insights you need to detect and mitigate CPU throttling issues in Kubernetes. By comprehensively tracking workload performance and resource utilization, groundcover alerts you to anomalies that could be a sign of throttling risks.
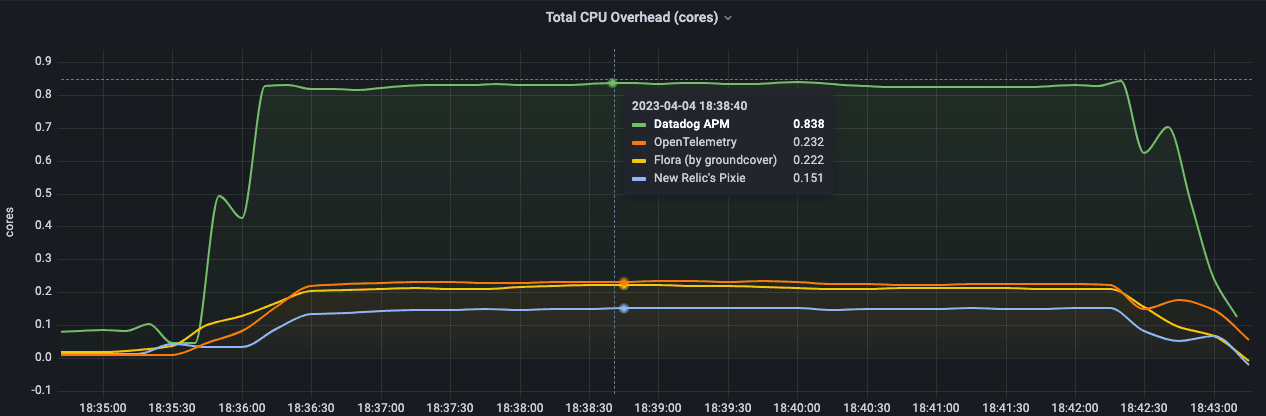
And when you do discover an issue, groundcover helps you drill down into the issue to determine whether it's a problem with your container or Pod configuration, node CPU availability, requests or limits, or something else.
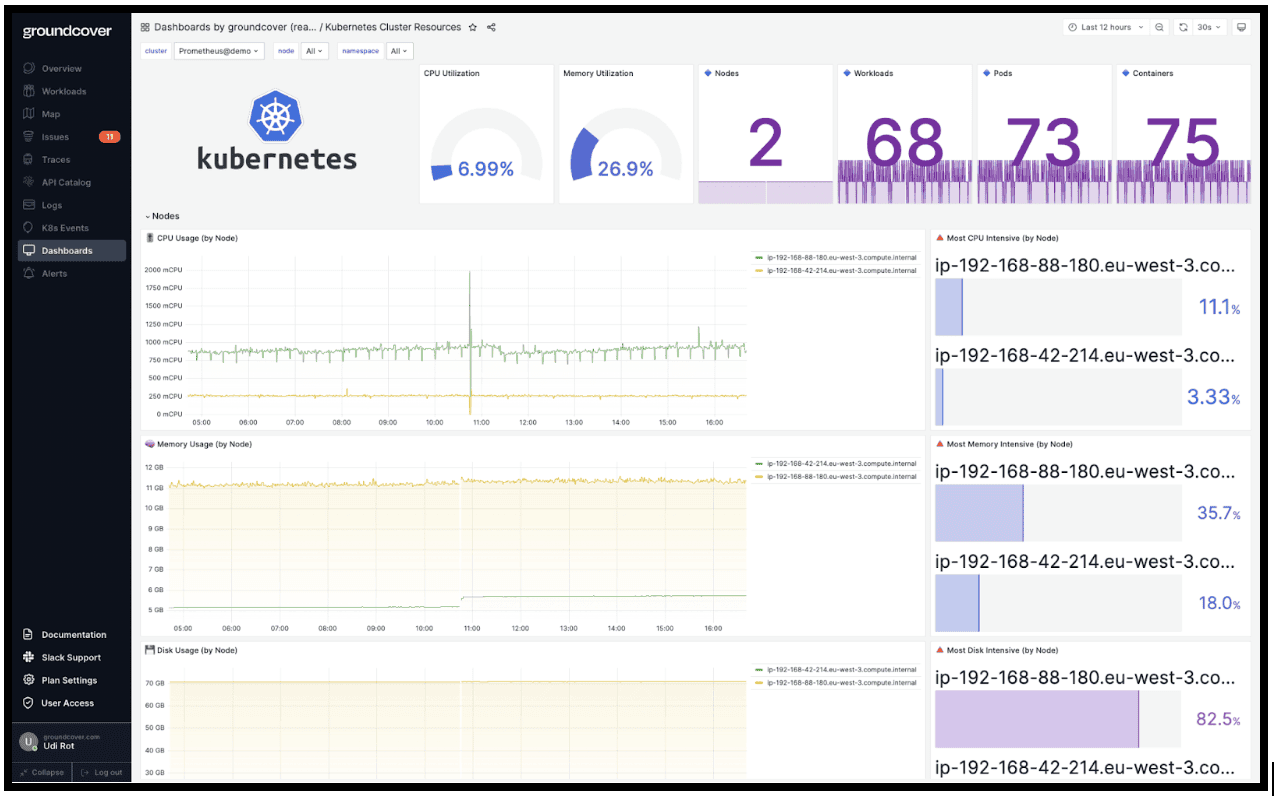
In a perfect world – or at least a perfect Kubernetes cluster – CPU throttling would never happen. But it can happen if you don't set the right CPU limits and requests, or if you lack continuous visibility into CPU utilization and throttling events. Avoid these risks by making strategic choices about CPU management in Kubernetes, as well as monitoring for CPU throttling on an ongoing basis.
CPU is a compressible resource in Linux, so Kubernetes slows workloads through throttling instead of terminating them when limits are exceeded.
Explore Kubernetes performance concepts.
CPU throttling usually appears as unexplained latency spikes even when overall CPU utilization appears moderate.
Learn more about Kubernetes metrics and monitoring.
CPU limits enforce strict scheduling quotas per container, meaning throttling can occur even if unused CPU exists on the node.
Learn more about Kubernetes resource management.
CPU limits should be removed for latency-sensitive services where throttling is more damaging than temporary CPU bursts.
Discover cluster resource scaling strategies.
Most observability stacks focus on application metrics and miss kernel-level scheduling behavior where throttling actually occurs.
Learn more about eBPF-based observability.
Keep up with all things cloud-native observability.
We care about data. Check out our privacy policy.
Monitor everything, deploy in minutes.
Cover your entire Kubernetes stack instantly
with no code changes.
Auto-detect issues across your entire cluster.
See it all. Store what matters. Pay Accordingly.

Meet the groundcover team for a 30 minute live session
Explore how groundcover provides instant, out of the box insights across logs, traces, metrics, and more.
Get a walkthrough of the platform, pricing model, and real world use cases tailored to modern observability challenges.
Ask anything- our team will address your specific stack, scale, and deployment needs.








By submitting this form you agree to our friendly privacy policy.

.svg)
.jpg)
